试题详情
K-近邻分类算法是指:一个样本在特征空间中的 k 个最相邻的样本中的大多数属于某一类别,则该样本也属于这个类别。如图所示有一坐标轴,横纵坐标分别为一部电影中搞笑镜头的个数和打斗镜头的个数。动作片中打斗镜头较多,喜剧片中搞笑镜头较多, 因此体现在坐标轴中,动作片集中在左上,喜剧片集中在右下。现要实现如下功能:输入某部电影的搞笑镜头和打斗镜头数目后,输出可能的类型,并在坐标轴中体现,如图三角形所示。
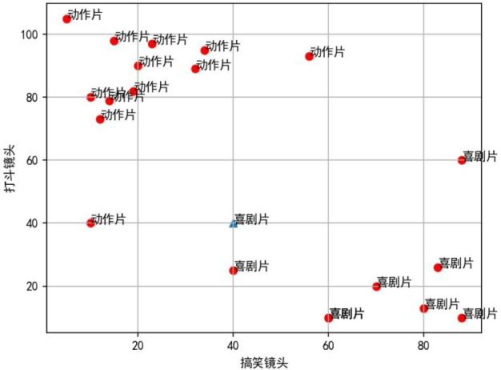
例如:
①输入搞笑镜头40和打斗镜头40:
②计算点(40,40)和其余所有点的距离(两点间的距离计算公式:
③将所有样本按照距离排序;
④假设k=3,取前k个距离的样本;
⑤统计出在前k个距离中,出现频次最多的类别,则(40,40)就属于该类别,可能是喜剧片。